導入
こんにちは!Pythonとロジスティック回帰を使って株価の動きを予測する方法についての冒険です。具体的には、「最新の日の高値と始値が1%以上上昇したかどうか」を予測してみます。このブログ記事では、私たちが使用したコードと、そのプロセスを分かりやすく解説していきます。初心者から中級者の方々に向けて、カジュアルに、そして理解しやすいように進めていきましょう。
データ準備と前処理
まず最初に、私たちはstock_data.csvというCSVファイルから株価データを読み込みます。このデータには、異なる日付と異なる株の開始価格(open_price)と最高価格(high_price)が含まれています。特定の日付のデータを抽出し、その日の株価の開始価格に対する最高価格の上昇率を計算します。そして、上昇率が1%以上かどうかでフラグを立てます。
このプロセスを通じて、私たちは機械学習モデルに入力するためのデータを準備します。その後、データを訓練セットとテストセットに分割し、特徴量データの標準化を行います。データの準備が整ったら、いよいよモデルの訓練へと進みます。
モデルの訓練と評価
ロジスティック回帰モデルを訓練する過程は、データサイエンスの魔法のようなものです。私たちはLogisticRegressionクラスを使用して、モデルを訓練しました。そして、訓練されたモデルを使用してテストデータセット上で予測を行い、その精度を評価しました。
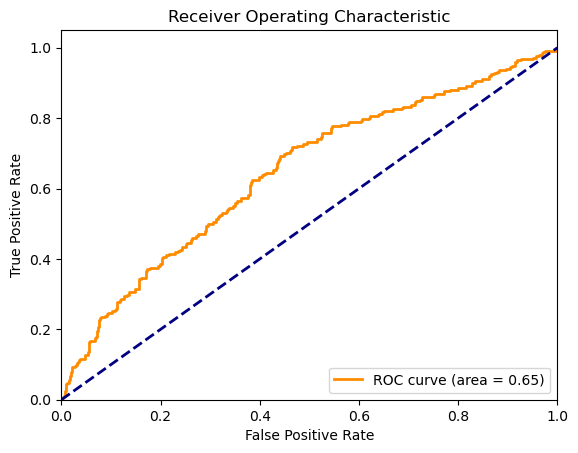
結果の評価には、AUCスコア、混同行列、そして分類レポートを使用しました。AUCスコアは0.647となり、これはモデルがランダムな予測よりも優れていることを示していますが、完璧からは程遠い結果です。混同行列と分類レポートからは、モデルの精度、再現率、F1スコアを詳細に理解できます。具体的には、真陽性(TP)が87、真陰性(TN)が373、偽陽性(FP)が74、偽陰性(FN)が164でした。これらの数値は、特に偽陰性の高さが課題であることを示しています。
結論と今後の展望
この冒険を通じて、ロジスティック回帰を使った株価の動きの予測について学びました。結果は完璧ではありませんが、この分析から得られる洞察は非常に価値があります。特に、モデルの改善に向けてのさらなる分析や、他の機械学習技術の試用が考えられ
コード
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score,roc_curve, auc, roc_auc_score, confusion_matrix, classification_report
from sklearn.model_selection import train_test_split
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# CSVファイルをDataFrameとして読み込む
csv_file = 'stock_data.csv'
stock_hist_df = pd.read_csv(csv_file)
# '2024-01-26'のデータを抽出
specific_date_df = stock_hist_df[stock_hist_df['date'] == '2024-01-26']
# open_priceに対するhigh_priceの上昇率を計算
specific_date_df['increase_flag'] = ((specific_date_df['high_price'] - specific_date_df['open_price']) / specific_date_df['open_price'] >= 0.01).astype(int)
# codeをインデックスとするDataFrameを作成
result_df = specific_date_df.set_index('code')['increase_flag']
# 株価上昇額を計算
stock_hist_df['price_increase'] = stock_hist_df['high_price'] - stock_hist_df['open_price']
# 日付を日付型に変換(必要に応じて)
stock_hist_df['date'] = pd.to_datetime(stock_hist_df['date'])
# コード毎にグループ化して、各日付の株価上昇率を列にする
pivot_df = stock_hist_df.pivot_table(index='code', columns='date', values='price_increase')
# result_df と pivot_df を code を基に結合
merged_df = pd.merge(result_df.reset_index(), pivot_df.reset_index(), on='code', how='inner')
merged_df = merged_df.drop(columns=pd.to_datetime("2024-01-26"))
merged_df = merged_df.dropna()
# ターゲット列と特徴量列を分離
X = merged_df.drop(columns=['increase_flag']) # ここで'target'はターゲット列の名前
y = merged_df['increase_flag']
# 訓練セットとテストセットに分割
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 特徴量DataFrameの列名をすべて文字列型に変換
X_train.columns = X_train.columns.astype(str)
X_test.columns = X_test.columns.astype(str)
# データの標準化
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
# ロジスティック回帰モデルを訓練
model = LogisticRegression(max_iter=1000)
model.fit(X_train_scaled, y_train)
# 予測と評価
predictions = model.predict(X_test_scaled)
accuracy = accuracy_score(y_test, predictions)
print(f'Accuracy: {accuracy}')
# predict_probaは各クラスに属する確率を返すため、陽性クラス(例えば、1)の確率を取得
y_score = model.predict_proba(X_test_scaled)[:, 1]
# ROCカーブの計算
fpr, tpr, thresholds = roc_curve(y_test, y_score)
# AUC(Area Under the Curve)の計算
roc_auc = auc(fpr, tpr)
# ROCカーブの描画
plt.figure()
plt.plot(fpr, tpr, color='darkorange', lw=2, label='ROC curve (area = %0.2f)' % roc_auc)
plt.plot([0, 1], [0, 1], color='navy', lw=2, linestyle='--')
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('Receiver Operating Characteristic')
plt.legend(loc="lower right")
plt.show()
# 予測クラスを取得(閾値0.5を使用)
y_pred = model.predict(X_test_scaled)
# AUCスコアの計算
auc_score = roc_auc_score(y_test, y_score) # y_scoreは、predict_probaによる予測確率の陽性クラスの値
print(f'AUC Score: {auc_score}')
# 混同行列の出力
conf_matrix = confusion_matrix(y_test, y_pred)
print('Confusion Matrix:')
print(conf_matrix)
# 分類レポートの出力
class_report = classification_report(y_test, y_pred)
print('Classification Report:')
print(class_report)